
Preface
Article Sidebar
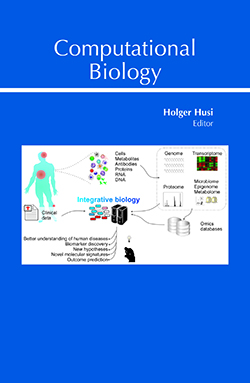
Main Article Content
Computational biology is nowadays one of the cornerstones in biological and medical data analysis and has a long and proud history originating in the 1960s from the fields of biophysics and protein biochemistry, notably the modeling of enzymatic reactions and other kinetic parameters. With the advent of improved and easier to access computing systems came the possibility of exploring biological systems to a much greater depth, especially linked to large-scale analytics platforms of biological samples, such as whole-genome sequencing tools, arrays, mass spectrometry, and many more. Such a considerable volume of data procured in a fast-paced technology-dependent manner required new ways to handle, manage, and analyze the information through improved data analytics streams, which was accomplished by borrowing and applying know-how from other sciences, such as mathematics, statistics, and computer sciences to biology, medicine, and disease analysis. This led to a vast expansion of data repositories and available computational tools feeding into reference databases and constantly improving our understanding of complex biological mechanisms. Ultimately, our ability to handle vast amounts of complex data enables us to integrate the various data streams into a contextualized system through systems approaches, network analysis, and modeling methodologies. Although it is evident that many gaps in our understanding of how any given biological system works still remain, more powerful systems, platforms, and procedures have started to emerge, such as automated decision machines, artificial intelligence, pattern matching approaches, and integrated and integrative data handling protocols, which will help us to continue uncovering new insights. CONTINUE READING…..
Downloads
Article Details

This work is licensed under a Creative Commons Attribution-NonCommercial 4.0 International License.